Comprehensive MLOps Architecture on GCP Vertex AI: Governance for ML Models and Data
- Arash Heidarian
- Jul 25, 2025
- 14 min read


Table of contents
Introduction
MLOps solutions on almost all cloud platforms are not mature enough and are still getting updated frequently. Many features and capabilities get deprecated, while the new updates may still not do the job as expected. Documentation is poor and confusing for many services. This all means that using great tools like Vertex AI on GCP requires just a little bit of trial and error. LLM tools like ChatGPT can help, but simply because many resources and concepts related to MLOps solutions are new, LLM models hallucinate even more than expected.
In this blog post, I try to cover tricks on building machine learning pipelines, using feature stores and model registries, and preparing monitoring and alerting.
Why do we need MLOps tools nowadays? I have dedicated another blog post to explain what is the difference between DevOps and MLOps. In this post (in Easier done than said section) I also briefly cover why modern MLOps (using MLOPs tools) is preferred, compared to traditional MLOps (using DevOps methods). Bear in mind that using modern MLOps tools doesn't mean DevOps practices are not required anymore, read my post on why modern MLOps tools and DevOps approaches need to be used side-by-side for CI/CD/CT processes. Remember, all tools provided in MLOps solutions by GCP, Azure, and AWS can actually be built from scratch. However, the purpose of using MLOps tools is to have all of them under one roof, governed and integrated in a single ecosystem.
In this post, I explain how to use Vertex AI services such as Feature Store, Model Registry, Batch Prediction, Pipelines, and Monitoring to productionize ML models. I also explain how Vertex AI uses other GCP services under the hood and how to configure the entire workflow. This post goes beyond a tutorial—I've tried to explain tips and tricks that are not usually or easily found in GCP documentation. I also try to answer some of common questions and concerns related to using Vertex AI sub-services.
Feature Store
As a very general practice for the majority of data science projects, the first step is to get the data, clean it, preprocess it, and build a dataset consisting of the right features. All MLOps solutions provide a feature store where feature sets can be stored, shared, analyzed, and retrieved (read about feature store here).
Feature Store? Why bother?
In Vertex AI, accessing and ingesting data into the Feature Store is only feasible via BigQuery tables. If that's the case, then why do we need to use the Feature Store at all? Has Google just tried to tick the boxes and sell a useless tool that literally acts as a mediator between data science pipelines and BigQuery? I have seen these questions and judgments all over the internet.
But what many never pay attention to are the capabilities that the Feature Store provides on GCP.

Feature store on Vertex AI come with:
Monitoring: It has a powerful monitoring service for drift detection, historical data ingestion, and a lot of automatically collected metadata and statistical information.
Drift Detection: Detects data drifts over time, across different data ingestion. Distribution changes can also be seen on the dashboard, which is automatically generated and visible for all features. Alerts can be managed so that if any drift is detected, users get notified. Drift thresholds can be set for both numerical and categorical data.
Data Snapshot: The snapshot capability helps access the latest records from a particular snapshot. It handles deduplication and null values. The snapshot mechanism is more powerful than you might think—see the documentation [here].
Strict Format Control: Feature Store doesn't allow data type changes. This means any change in the nature of the data or a poor data preprocessing job will result in failed data ingestion into the Feature Store.
Low Latency for Online Data Access: Batch prediction for offline data access is also available.
API Serving: Supports both online and offline access.
However, we can’t simply look inside the Feature Store. Any data ingestion and retrieval must happen using a table in BigQuery. Figure 1 shows how this process works.

Feature Store Architecture
Data ingestion into the Feature Store requires data to be first stored in a BigQuery table, which the Feature Store then uses as a source. Similarly, retrieving data from the Feature Store often involves creating a BigQuery table to store the extracted feature values. This tight coupling between Vertex AI and BigQuery is fundamental to the Feature Store's architecture and functionality.
Data Ingestion Process
The process of ingesting data into Vertex AI Feature Store involves the following steps:
Data Preparation: The raw data, which could originate from various sources, needs to be transformed and structured into a format suitable for the Feature Store. This typically involves data cleaning, feature engineering, and ensuring data consistency.
BigQuery Table Creation: A BigQuery table is created to hold the prepared data. The schema of this table should align with the feature definitions defined in the Feature Store. This table acts as the staging area for data ingestion.
Data Loading into BigQuery: The prepared data is loaded into the newly created BigQuery table. This can be achieved using various BigQuery loading methods, such as batch loading from Cloud Storage or streaming ingestion.
Feature Store Ingestion: The Feature Store is configured to ingest data from the BigQuery table. This involves specifying the BigQuery table as the data source and mapping the table columns to the corresponding features in the Feature Store.
Data Materialization: The Feature Store reads the data from the BigQuery table and materializes it into its internal storage format, optimized for low-latency feature serving.

Streamlining Data Ingestion Into Vertex AI Feature Store
Diagram 1 shows a cloud architecture for data processing step in Vertex AI pipeline using Google Cloud tools: Python scripts in a Docker environment prepare data, batch loaded into Cloud Storage, transferred to a BigQuery staging table, and ingested into Vertex AI Feature Store.

Data Retrieval Process
Retrieving data from Vertex AI Feature Store also involves BigQuery:
Feature Selection: The user specifies the features they want to retrieve from the Feature Store. This selection is based on the requirements of the machine learning model or application that will consume the features.
Entity Identification: The user provides the entity IDs for which they want to retrieve the features. These entity IDs correspond to the entities stored in the Feature Store.
Feature Retrieval Request: A feature retrieval request is submitted to the Feature Store, specifying the selected features and entity IDs.
Data Extraction: The Feature Store extracts the feature values for the specified entities and features from its internal storage.
BigQuery Table Creation (Optional): A BigQuery table can be created to store the extracted feature values. This is useful for offline analysis, model training, or integration with other BigQuery-based workflows.
Data Loading into BigQuery (Optional): The extracted feature values are loaded into the newly created BigQuery table.
Data Consumption: The extracted feature values, either directly from the Feature Store or from the BigQuery table, are consumed by the machine learning model or application.

Diagram 2 illustrating both data retrieval and ingestion from and into feature store, via BigQuery. As discussed earlier, for ingestion, data need to be stored in initial table/staging table first. Also for data retrieval it is recommended to store the extract into a Big Query table for further use.

Model Registry
Model Registry comes with a lot of benefits and sub-services. I just want to cover the ones that I found to be game-changers and tremendous time-savers.
Versioning: The biggest advantage of Model Registry is its auto-versioning and metadata. Every time a new model is trained, a new version is added and versioned automatically. Each version can be equipped with a Docker image. The models are stored in Cloud Storage. Switching between different versions is as easy as using a drop-down list.
Comparison & Benchmarking: Moreover, all versions can be linked to an Experiment. This means that in the Experiment menu in Vertex AI, you can easily compare all versions and evaluate their performance and accuracy in a dashboard that is automatically generated.

Easier done than said
In the traditional MLOps approach (which employed DevOps practices), all the services mentioned above had to be built by an internal team, which took a lot of time, and maintenance was cumbersome.
With Model Registry tools, all it takes for data scientists and the entire team is to use an API or Python SDK to register their models, along with metadata and accuracy reports. The rest is taken care of and is easily accessible via MLOps tools. Remember, all different sections in MLOps ecosystems are seamlessly connected. Model versions, batch prediction, training datasets, inference data, metadata for both data and models, model accuracy, and more are linked and trackable from a single platform (Vertex AI for GCP, Azure ML for Microsoft, and SageMaker Pipelines for AWS). No matter what platform you use, they all provide very similar interfaces and services.
Dashboard tracking and switching between different versions are all doable with a few clicks, SDKs and APIs are available for any modifications and changes.

Model Registry Architecture
Model Registry in Vertex AI uses Cloud Storage buckets in the background to keep the models. We don’t need to worry about how the entire system takes care of versioning; all we need to be aware of is preparing the infrastructure properly.
Model Registry requires the following three key steps:
Model Training: Ideally, this should be done using a Docker image if we are aiming for best practices. But it can also be done on a Jupyter Notebook, local machine, or anywhere. Then the model artifact pickle file needs to be stored on a local drive—old school, right? Yes, just the same way we have always been doing it.
Cloud Storage Bucket: The model artifact then needs to be copied into a Cloud Storage bucket, as this is what Model Registry uses under the hood. To make sure we do not overwrite older versions, each model should be placed in a distinguishable folder path. An easy approach would be folders named by date and time. Model Registry links each version to its path automatically. The model/artifact MUST be called model or model.pkl, and MUST be placed in a subfolder called model; otherwise, Model Registry will not pick it up. This means each path/directory/folder in the bucket’s path must only contain one model.
Deploy Image: Registering a model requires specifying a deployment image—it’s not optional, it’s a must. If the goal is solely to register the artifact for versioning and retrieval—without intending to deploy it—you can use a lightweight placeholder image such as gcr.io/google-containers/pause:3.1. This image, commonly used in Kubernetes and GCP environments, is extremely small (around 300 KB) and simply “pauses” without performing any real work. It’s ideal for satisfying API requirements when actual serving functionality is not needed. If the purpose is to serve the model using an endpoint, make sure you create the right Docker image, store it in Artifact Registry, and link it to the model during the registration process.
Diagram 3 illustrating the workflow of training and deploying a machine learning model. The process starts with model training on a local machine, producing a model.pkl file. This file is then uploaded to a cloud storage bucket, tagged with date and time, and registered with the Vertex AI Model Registry. A Docker image, created and stored in an artifact registry, supports the model training and deployment processes.

Batch Prediction
At the end of the day, it’s all about consuming trained models, isn’t it? Vertex AI has the batch prediction service, and it’s quite flexible to get and insert its input and output data from and into various sources.
Using the service, though, is not hassle-free, and configuration is more complicated than it looks in tutorials and GCP documentation pages.
Let’s see if it’s actually worth it.
Batch Prediction Service? Why bother?
Again, the same question: why bother using such a service with such a convoluted architecture (I will explain the architecture later)? Consuming models and creating batch predictions is much easier and faster using classic Pythonic .predict()! All can be done and dusted in an hour, no hassle. Why suffer and get out of your comfort zone?! Why spend days setting up a Vertex AI batch prediction job?
Here are a few pros you gain:
Monitoring: Every time a model is triggered and consumed, it can be easily monitored via the Vertex AI Batch Prediction menu. Each job collects a lot of metadata automatically, and much more metadata can be customized and added. Metadata such as the source and destination of input and output data, model version, features, date and time, and much more.
Drift Detection: I would call this the most useful feature of the Batch Prediction job! When you set up a batch prediction job, you can also specify the training dataset (the dataset used to train the model). Every time the model is consumed in the inference pipeline, inference data are automatically compared to the training dataset. If any drift is detected, you get notified.The data drift detected at this stage may mean either the nature of the data is changing and the trained model is getting outdated (so a freshly trained version needs to be considered), or it can be an indication that something is broken in the data flow upstream, maybe in ETL or data preprocessing!The distribution comparison happens on all features, and regardless of whether drift is detected or not, you can always see the bar chart distribution between inference and training datasets for each feature!
The pros and benefits of using the batch prediction job may be even more than what I explained above, but the gems above were the most exciting and useful ones I could spot.
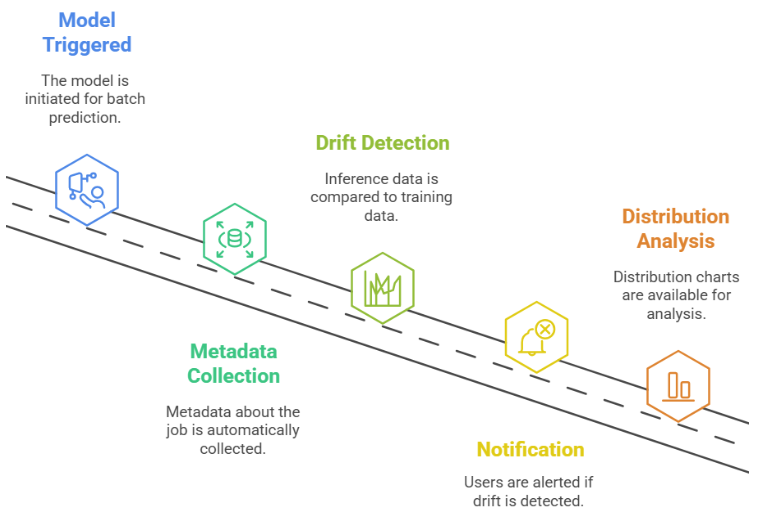
Batch Prediction Architecture
Batch prediction job service is well-integrated with Model Registry, where you can point to the right model you want to use and set a few other parameters to get all the gems mentioned above. The following are required to be prepared and passed to the batch prediction job:
Target Model: All you need to do is pass the name of the target model; the version can also be defined.
Inference Data Source: Inference data can be picked from different resources including BigQuery tables or various files from Cloud Storage. In this blog post, we focus on tabular data in BigQuery.
Output Destination: After the model is consumed and the results are generated, the results can be placed in different destinations such as a BigQuery table or Cloud Storage.
Machine Type: Make sure you define the right Kubernetes machine with the appropriate size.
Model Monitoring & Alerting: This is where you need to define the training dataset (link the BigQuery table which holds the training set). This dataset is used to compare inference data and detect any drift. Alerts can be set on any detected data drift or data skew.
Diagram 4 shows a batch prediction workflow using Vertex AI. It shows the flow of datasets from BigQuery through a Batch Prediction Service, interfacing with a Model Registry and performing drift/skew detection, to produce an output dataset.

Vertex AI Pipelines
Typical workflows for the majority of data science projects go through two major pipelines: Model Training and Inference (Model Consuming). Both pipelines usually consist of subtasks, which in GCP are called components. Each component requires:
Script: Usually a Python script that executes a task and resides in a git repo.
Docker Image: To execute the script on. It should be registered in Artifact Registry.
Kubernetes Machine Type: Defines the required hardware resources to execute the task.
Components can take inputs from and place outputs in different resources (e.g., BigQuery, Cloud Storage, or external sources). Components can also pass light inputs and outputs to each other.
Multiple connected components shape a pipeline in Vertex AI. The pipeline can be scheduled, and after each execution, tons of metadata are collected, which helps with monitoring and tracking.
From Siloed to Synced: Shared Resources
Ideally, the training and inference pipelines should be able to talk to each other. For instance, a single change in data preparation or feature engineering may affect the entire process downstream or in another pipeline. Even if the change doesn’t necessarily break the pipeline’s functionality, it may result in producing incorrect or misleading results. Sharing resources helps prevent tasks and components from working in silos. Eventually, any required change can be easily reflected in the entire process, without the need for hours of manual tracking of where and how a change may affect other processes.
Some recommended shared resources are:
Shared Component: If there is any particular task, such as Data Preparation, which is supposed to be repeated in both pipelines with minor differences, then try to use the same component in both pipelines. That way, changing one is automatically reflected in the other.
Shared Configs: Ideally, all configs should be placed in YAML config files that both pipelines can access. This includes dataset names, feature lists, model names, model hyperparameters, bucket names, test and training intervals and logic, regions, project IDs, and more.
Shared Services: The model training pipeline trains and registers a model in Vertex AI Model Registry. This is where the inference pipeline gets the model from. The training pipeline also prepares the training and test sets, which are stored in Vertex AI Feature Store. The same feature store can be used in the inference pipeline where the batch prediction job is created.
Shared Docker Image: Usually, data scientists develop their entire work in a single (virtual) environment. This means all different versions of Python and its dependencies are the same across all components. Hence, one Docker image should be created and stored in Artifact Registry to be used by all components.

Diagram 5 shows how training and inference pipelines, including shared resources like Artifact Registry, Vertex AI Model Registry, Feature Store, Big Query and Cloud Storage data resources, and shred component (containing shared scripts). The shared resources are highlighted and connected in yellow frames.

Monitoring
The monitoring capabilities in GCP are quite broad. They can stretch from log and metadata collection to detailed embedded services on top of each sub-service. Here, we summarize a few crucial ones for MLOps work:
Logs: Not only does every service in Vertex AI collect logs, but scripts developed by data scientists can also use the GCP logging SDK to send additional logs to the GCP logging service. It is recommended for data scientists to prepare logs related to performance, tests, validations, and important reporting—either statistical logs used technically by data scientists for reviewing and auditing, or general information that can be used by managers and end users. GCP logs can also be explored using GCP log query with TypeScript, which helps fish out the required information from tons of collected logs. Information collected from logs can also be linked to GCP Alerting Channels to notify end users via different channels such as email and chat.
Drift Detection: As discussed in detail previously, many ML services in Vertex AI, such as Feature Store and Batch Prediction, have drift detection mechanisms embedded in them. Data scientists just need to configure them to trigger alerts based on predefined thresholds.

Summary
Using MLOps tools such as Vertex AI is always a matter of debate due to its complexity and dependency on classic services. Many argue against its efficiency, as the same functionalities can often be built in a much faster and easier way. Yes, we can still keep using traditional MLOps, where classic DevOps practices play a major role. But the Achilles' heel of traditional MLOps is its maintenance and complex governance—if there is any at all.
Using modern MLOps tools such as GCP Vertex AI, Microsoft Azure ML, or AWS SageMaker Pipeline helps bring governance and monitoring under one roof. These tools act as mediators (or portals, if you like) between infrastructure layers such as databases, storage, and security. They facilitate automatic model versioning, data snapshots, scalable pipeline execution, embedded monitoring and drift detection mechanisms (both at the model and data level), automatic metadata collection, traceability and connectivity tracking across all elements and services, and easy-to-use dashboards for further analysis and auditing if required.
From the inside
Little bit of a background about this chapter of my blog posts: Since GenAI, LLMs, Robots and Online Interactions predominantly turning humanity into merely virtual online characters, the only thing which makes us superior to them, is our genuine words and emotional depth. Hence, I decided to add this short chapter in my blog posts, to make it more humanized. In the era of cheap and easy machine-generated texts, with the hope of adding my two cents in generating genuine words coming From The Inside of a human heart and soul, rather than a cold-wired machine.
My note for this blog post:
Morpheus, 1999: We have only bits and pieces of information but what we know for certain is that at some point in the early twenty-first century all of mankind was united in celebration. We marveled at our own magnificence as we gave birth to AI...A singular consciousness that spawned an entire race of machines. We don’t know who struck first, us or them!!!



Comments